
There is a new technique for using agents which is catching on, most notably with autoresearch from @karpathy. The core of it is a simple, powerful feedback loop:
- agent has an idea
- agent implements a change to test that idea
- agent evaluates change
- agent keeps or discards based on eval results
- agent loops back to step 1 and iterates
With a clear goal and an easy way to measure progress against that goal, agents can rip through this feedback loop over and over with little oversight. The feedback they need to make decisions comes from the evaluation itself. Did the idea improve the metric? If yes, keep it. If no, discard it. Iterate. Done right your agents can literally work for days this way:
Not mine, but someone I know feedback loop maxxing
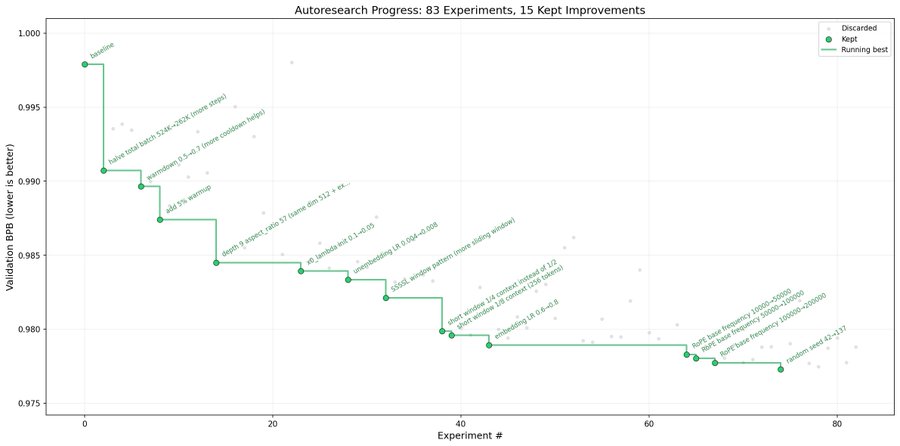
For @karpathy's autoresearch the metric was validation bits per byte, measured from a 5 minute LLM training run. He gives agents an easy way to execute that run and has them run overnight, continuously optimizing for his metric. The overnight result is captured here:
Feedback loops like this are extremely powerful. And they generalize easily to other domains. KernelFactory was a recent project of mine that used a feedback loop with agents in a similar way: https://x.com/bertcmiller/status/2024559931479773271
There the core task for agents was to optimize a kernel with no human intervention. The feedback loop looked like this:
- Come up with a hypothesis on what is limiting the kernel's performance (often agents would write scripts to help their analysis)
- Make a change based off of that hypothesis
- Run a test to see if the kernel is correct and if the change improved performance
- If the kernel is correct and faster, keep the change. If not, discard it.
- Go back to 1 and loop again.
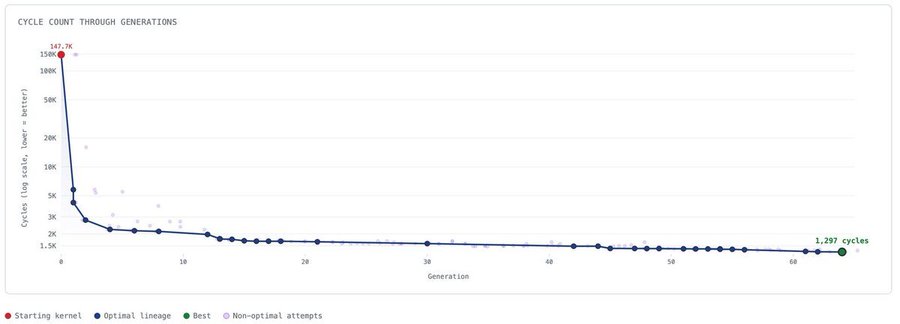
Over many iterations of this feedback loop agents created optimization after optimization until I stopped their progress at around 100x improvement from where they started:
At the core KernelFactory works very similar to autoresearch. It differs mostly in problem domain and that KernelFactory is built to have many agents run in parallel and no human intervention end-to-end. As a result it can be scaled up a lot more, leading to better results and more sustained effort over long periods of time. It's not hard to imagine autoresearch having this, indeed I shipped a basic proof-of-concept myself: https://x.com/bertcmiller/status/2030641691560911251
Part of what's powerful about having many agents is that they can explore many different paths. For problems with an unclear path forward this makes it faster to make progress and helps prevent getting stuck in local optima. One agent might exploit a branch of optimization that is promising immediately but ends in a dead end, while another explores a path that doesn't immediately pay off but does lead to sustained progress.
A final thing about the power of agents and feedback loops is that they don't need to one shot the task. If they fail the first time, or even the first 50 times in a row, they can simply start over and try again with something different. Agents just need to have a non-zero hit rate of improving against your benchmark. Then, with enough iterations, you will get progress. Obviously this isn't economical everywhere, but for fields where marginal improvements matter a lot it is super powerful.
It is not hard to see how agents optimizing in clear feedback loops like this can apply to many, many other domains. Off the top of my head: performance engineering, ML infra, security (see: @paradigm / @openai work), etc stand out in pure software. All of these have strong feedback loops where correctness is verifiable, progress is measurable, and small improvements matter a lot.
The holy grail of the industry is AI r&d itself because improvements can compound recursively. It seems that we're at the beginnings of this with things like autoresearch, AlphaEvolve improving AI training and inference, and so on.
Relatedly, doing r&d in other scientific fields like biology or physics would also be extremely valuable. I would argue that the first task is figuring out how to get a good feedback loop going. That is much harder to do in the real world. That is why things like automated wet labs are interesting: because they let agents run many, many experiments and keep iterating based on what works.
You can imagine something like this in physics too. And perhaps there's a lot of progress to be made without even needing a bridge to the physical world at all, as there already exists a lot of open source data to iterate on (e.g. galaxy images).
If you can get the feedback loop right then progress can come from applying compute to it. You set up the environment, summon a swam of agents, and they hill climb for you. So the pertinent questions are: what is the metric that you are optimizing for? And what is the feedback loop your agents?