MELLODDY and the Privacy and Accuracy Frontier
MELLODDY is a federated learning network where 10 major pharmaceutical companies are collaboratively training an algorithm on their collective pre-clinical data, with the goal of accelerating drug discovery. MELLODDY was borne out of the Innovative Medicines Initiative and is a 3 year project that has just hit their 1 year milestone. With this milestone they also launched their first run of live federated learning learning across MELLODDY’s member’s datasets.
The accompanying article is a good reminder of the difficulty of standing up a federated learning network. MELLODDY has spent a full year performing audits to ensure their software actually met the privacy and security standards that each party required to go live. Only after doing so could the MELLODDY network start to train their algorithms, and their first live run is planned to go on for months. I wonder what the bill is for the computing power they are using!
Turning to the future, they plan to spend the next 2 years focusing on “maximizing predictive gains from securely harnessing our joint private data.” I thought this was interesting and worth a bit of elaboration.
As you may recall one of the challenges in training a federated learning algorithm is that algorithms may contain some of the information used to train them. If you are trying to fit an algorithm closely to some data then you may end up embedding that data in your algorithm. In turn that means someone else could take your algorithm and reverse engineer it to yield the data you used to train it! Obviously this is a bad thing if your algorithm is trained on sensitive data that you want to keep private.
In simple terms you could think of this tradeoff like this:
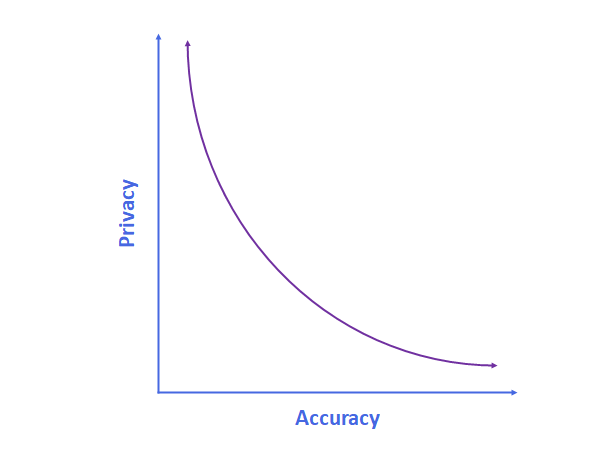
As you fit your algorithm to the underlying data closer it becomes more accurate. But, at the same time, there is an increasing risk of someone being able to reverse engineer your algorithm and be able to recover some of your sensitive data from it. This trade off between privacy and accuracy forms a frontier, which is the purple line above. Note: for a given level of privacy or accuracy you can never go beyond the purple line, but you can simply not reach it if your algorithm is not optimally designed.
In the case of MELLODDY the underlying data is highly sensitive and there is a minimum level of privacy that the companies involved demand:
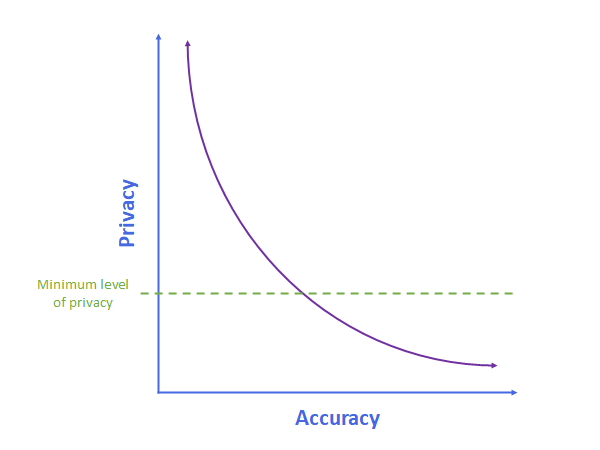
No matter what accuracy improvements they would get these companies are not willing to cross this line, and MELLODDY has spent their year so far performing audits to show can they can reach this minimum level of privacy. Their algorithm is represented by the blue dot “A” below.
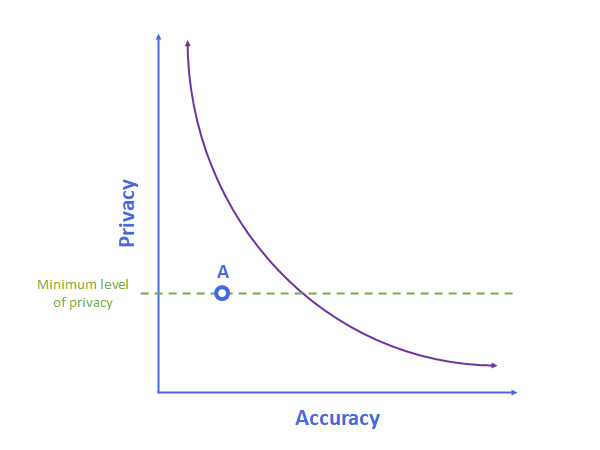
The reason why A is not on the purple line is that the focus of MELLODDY to date has been proving they can meet a minimum level of privacy, not optimizing their algorithm for accuracy. The next two years of MELLODDY is focused on improving accuracy while still ensuring that same level of privacy:
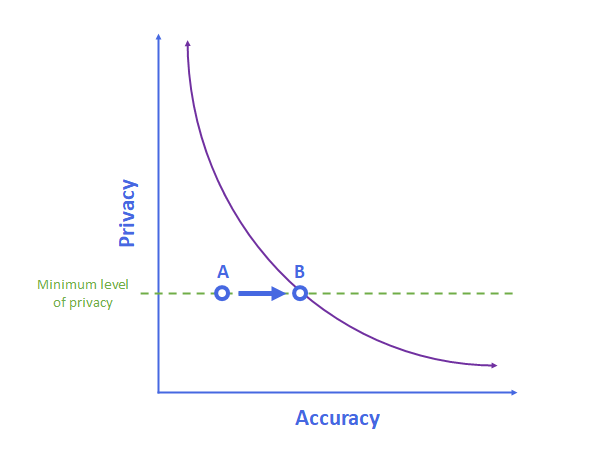
In other words, MELLODDY is trying to move from point A, where they are now, to point B, which is on the accuracy and privacy frontier. At this point they would be maximizing the accuracy of their algorithm given a certain minimum level of privacy.
These principles are broadly applicable across federated learning networks. Each network is faced with the same trade off between privacy and accuracy and will need to make a decision about the level of risk members are willing to bear. Moreover, each network will need to do the work of showing they have achieved their desired level of privacy. This is a non-trivial thing to do and will likely require independent audits by experts. Lastly, each network will need to do the work of optimizing their algorithms to the edge of the privacy-accuracy frontier, or moving from A to B, with the constraint of meeting their privacy needs.